iPAS AI應用規劃師 初級
L11203 資料隱私與安全
出題方向 (L11203 資料隱私與安全)
1
個人資料保護法 (PDPA) 基本概念
2
資料隱私原則 (最小化、目的限制)
3
資料安全基礎 (CIA Triad)
4
常見安全威脅與防護
5
隱私強化技術 (PET) 概念
6
AI 應用中的隱私風險
7
AI 應用中的安全風險
8
相關法規與指引 (金融、公部門)
#1
★★★★★
台灣《個人資料保護法》(PDPA, Personal Data Protection Act) 主要保護的對象是?
答案解析
《個人資料保護法》(PDPA) 的立法目的在於規範個人資料的蒐集、處理及利用,以避免人格權受侵害,並促進個人資料之合理利用。其保護的核心是與「生存之自然人」相關,且得以直接或間接方式識別該個人之資料。法人的資料或非關個人的數據不在此法直接保護範圍內。
#2
★★★★★
根據《個資法》(PDPA),下列何者屬於特種個人資料 (Sensitive Personal Data)?
答案解析
《個資法》(PDPA) 第 6 條原則上禁止蒐集、處理或利用特種個資,除非符合特定例外情況。這些特種個資包括醫療、基因、性生活、健康檢查及犯罪前科。姓名、電子郵件、職業等雖然也是個資,但不屬於特種個資。處理特種個資需要更嚴格的法律依據和保護措施。
#3
★★★★★
在蒐集個人資料 (Personal Data) 時,僅蒐集與特定目的相關且足夠的資料,避免過度蒐集,這體現了哪個隱私保護 (Privacy Protection) 原則?
答案解析
資料最小化 (Data Minimization) 原則要求蒐集、處理及利用個人資料時,應與蒐集之特定目的有正當合理之關聯,並以有助於達成目的之最小範圍為限。也就是說,不應蒐集非必要的個人資料。這有助於降低資料外洩或濫用的風險。參考《公部門人工智慧應用參考手冊》4.3 節及《金融業運用人工智慧(AI)指引》第三章。
#4
★★★★★
要求個人資料 (Personal Data) 的蒐集、處理或利用不得超出蒐集時所聲明的特定目的範圍,這是指哪個隱私保護 (Privacy Protection) 原則?
答案解析
目的限制 (Purpose Limitation) 原則規定,蒐集個人資料時必須有明確、合法的特定目的,且後續的處理和利用不得逾越這些目的範圍。若要將資料用於原始目的之外的新用途,通常需要再次取得當事人同意或有其他法律依據。參考《公部門人工智慧應用參考手冊》4.3 節。
#5
★★★★★
資料安全 (Data Security) 的三大基本要素(CIA Triad)是?
答案解析
資訊安全領域普遍接受的 CIA Triad 模型,是資料安全 (Data Security) 的基石:
- 機密性 (Confidentiality):確保資料只被授權的使用者存取。
- 完整性 (Integrity):確保資料在儲存或傳輸過程中不被未經授權地修改或破壞,保持其準確和可信。
- 可用性 (Availability):確保授權使用者在需要時能夠及時存取和使用資料。
#6
★★★★
確保資料只能被經過授權的人員讀取或存取,這是指資料安全的哪個要素?
答案解析
機密性 (Confidentiality) 要求保護敏感資訊不被未經授權的個體(人、程式或系統)存取。常用的技術包括加密 (Encryption) 和存取控制 (Access Control)。
#7
★★★★
保護資料不被未經授權的竄改或刪除,確保資料的準確和可信,是指資料安全的哪個要素?
答案解析
完整性 (Integrity) 旨在維護資料的一致性、準確性和可信賴性,防止資料在儲存、處理或傳輸過程中被非法修改或破壞。常用的技術包括雜湊函數 (Hash Functions)、數位簽章 (Digital Signatures) 和版本控制。
#8
★★★★
確保授權使用者在需要時能夠順利存取及使用資料和相關系統,是指資料安全的哪個要素?
答案解析
可用性 (Availability) 指的是確保資訊系統和資料在需要時處於可操作狀態,並且能夠被授權用戶及時存取。影響可用性的威脅包括阻斷服務攻擊 (DoS, Denial of Service)、硬體故障、天災等。常用的保障措施包括備份 (Backup)、備援 (Redundancy) 和災難復原計畫 (Disaster Recovery Plan)。
#9
★★★★
使用加密 (Encryption) 技術來保護資料傳輸和儲存,主要是為了達成資料安全的哪個目標?
答案解析
加密 (Encryption) 是將原始資料(明文)轉換為無法輕易讀懂的格式(密文)的過程,只有擁有金鑰 (Key) 的人才能解密還原。其主要目的是防止未經授權者竊取或讀取敏感資訊,從而保障資料的機密性 (Confidentiality)。雖然某些加密技術也能輔助驗證完整性,但其核心目標是保密。
#10
★★★
設定不同使用者帳號具有不同的資料存取權限(例如,只能讀取、可以修改、可以刪除),這是屬於哪種安全控制措施?
答案解析
存取控制 (Access Control) 是一系列限制對資訊系統資源(包括資料、檔案、服務等)訪問權限的策略和技術。其目的是確保只有經過身份驗證 (Authentication) 和授權 (Authorization) 的使用者才能存取他們被允許使用的資源,並執行被允許的操作。設定不同權限是實現最小權限原則 (Principle of Least Privilege) 的一種方式。
#11
★★★★
將個人資料中的姓名替換為隨機編號,地址替換為較大的區域,以降低識別特定個人風險的技術,稱為什麼?
答案解析
去識別化 (De-identification) 的目的是移除或修改資料中的可識別資訊,使其難以直接連結回特定個人。假名化 (Pseudonymization) 是其中一種技術,用代碼或假名取代直接識別符(如姓名、身分證字號),但保留了透過額外資訊重新識別的可能性。這些技術皆屬於隱私強化技術 (PET) 的範疇。參考《金融業運用人工智慧(AI)指引》第三章提及的隱私保護處理。
#12
★★★
下列何者不是隱私強化技術 (PET, Privacy-Enhancing Technology) 的例子?
答案解析
隱私強化技術 (PET) 旨在在資料處理和分析過程中保護個人隱私。差分隱私透過添加噪音保護個體資訊,同態加密允許在加密數據上進行計算,聯邦學習讓模型在本地訓練而無需匯總原始數據。而PKI 主要是用於管理數位憑證和金鑰,以確保通訊安全和身份驗證,其主要目標是安全而非直接的隱私保護計算。
#13
★★★★
在 AI 應用中,即使資料已經過去識別化,仍可能透過分析關聯性推斷出個人身份的風險稱為?
答案解析
重新識別 (Re-identification) 指的是即使數據經過匿名或去識別化處理,攻擊者仍可能透過結合其他公開或可取得的資訊,反推出數據對應的原始個人身份。這對基於大量數據訓練的 AI 模型來說是一個重要的隱私風險,因為模型可能無意中學習到足以被用於重新識別的模式。推斷攻擊 (Inference Attack) 則泛指從系統的輸出或行為中推斷出不應被得知的敏感資訊。
#14
★★★★
惡意攻擊者透過在訓練數據中注入少量惡意或誤導性數據,企圖影響 AI 模型最終行為或使其產生錯誤判斷的攻擊手法稱為?
答案解析
數據中毒 (Data Poisoning) 是一種針對 AI 模型訓練階段的攻擊。攻擊者污染訓練數據,植入特定的錯誤或惡意樣本,使得訓練出來的模型在特定情況下會做出攻擊者想要的錯誤預測或分類,或者降低模型的整體性能。
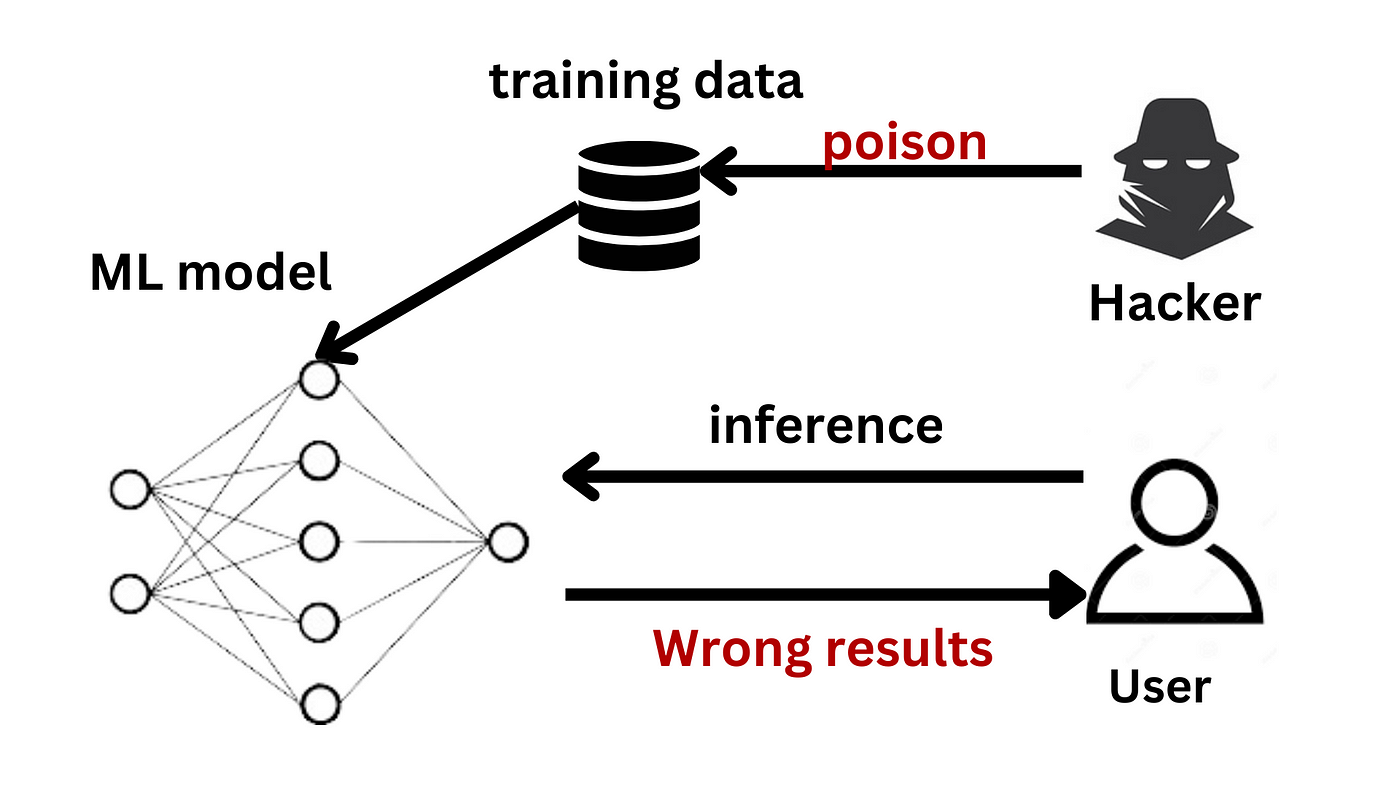
#15
★★★★
對已經訓練好的 AI 模型輸入經過精心設計、人眼難以察覺的微小擾動,導致模型做出錯誤判斷的攻擊手法稱為?
答案解析
對抗性攻擊 (Adversarial Attack) 主要發生在AI 模型的推論或應用階段。攻擊者產生對抗樣本 (Adversarial Examples),這些樣本對人類來說與正常樣本幾乎無異,但能欺騙 AI 模型使其輸出錯誤的結果。例如,在停止標誌圖片上添加微小的擾動,可能導致自動駕駛系統將其誤判為速限標誌。
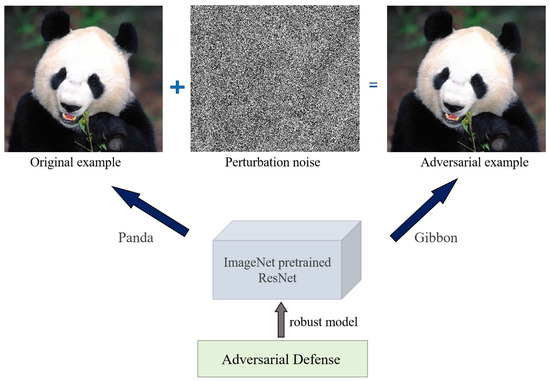
#16
★★★★
根據《金融業運用人工智慧(AI)指引》,金融機構在運用 AI 提供服務時,應尊重客戶的選擇權利,並提醒客戶什麼?
答案解析
《金融業運用人工智慧(AI)指引》第三章核心原則(二)及第四節強調,金融機構如運用 AI 系統向客戶提供金融服務,應尊重客戶選擇的權利,並提醒客戶是否有替代方案,以維護客戶權益。這體現了以客戶為中心和提供選擇的原則。
#17
★★★★
《公部門人工智慧應用參考手冊》4.4 節提到 AI 資安議題,其中「提示注入攻擊 (Prompt Injection Attack)」主要針對哪類 AI 系統?
答案解析
提示注入攻擊 (Prompt Injection Attack) 是一種針對基於大型語言模型 (LLM) 的系統(例如 ChatGPT 或其他聊天機器人、文本生成 AI)的安全漏洞利用方式。攻擊者透過精心設計的輸入提示 (Prompt),誘使或操控模型忽略其原始指示,執行攻擊者意圖的行為,例如洩露敏感資訊、產生不當內容或繞過安全限制。
#18
★★★★
根據台灣《個資法》(PDPA),當事人對於其個人資料 (Personal Data) 擁有哪些主要權利?
答案解析
《個資法》(PDPA) 第 3 條明確賦予當事人對其個人資料擁有多項權利,包括:
- 查詢或請求閱覽。
- 請求製給複製本。
- 請求補充或更正。
- 請求停止蒐集、處理或利用。
- 請求刪除。
#19
★★★
根據《公部門人工智慧應用參考手冊》1.6 節所列法規,下列何者與保護創作或發明較為相關?
答案解析
《公部門人工智慧應用參考手冊》1.6 節列出的八部法律中,著作權法 (Copyright Act) 保護文學、科學、藝術或其他學術範圍之創作;專利法 (Patent Act) 保護發明、新型或設計;營業秘密法 (Trade Secrets Act) 保護具有經濟價值的秘密資訊;商標法 (Trademark Act) 保護商品或服務的標識。這些都與保護智慧創作或發明有關。個資法保護個人資訊,資安法保護資通系統安全,政府資訊公開法促進資訊透明。
#20
★★★
哪種隱私強化技術 (PET) 允許在不解密數據的情況下直接對加密數據進行計算?
答案解析
同態加密 (Homomorphic Encryption) 是一種特殊的加密技術,它允許對密文直接進行特定的數學運算(如加法、乘法),運算結果解密後與對明文進行相同運算再加密的結果一致。這使得可以在不暴露原始敏感數據的情況下,對加密數據進行處理和分析,極大地增強了數據隱私。
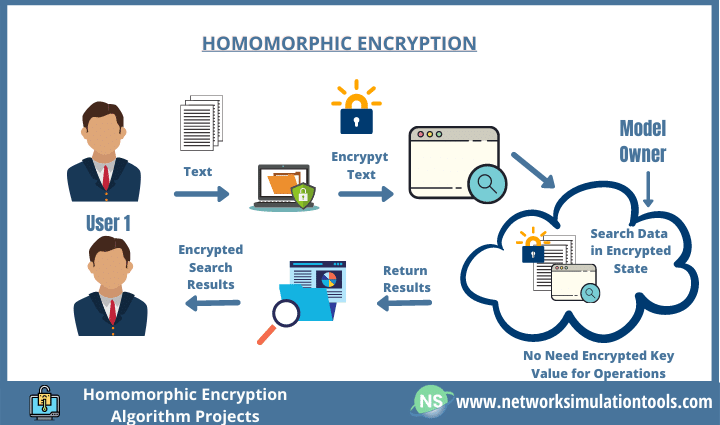
#21
★★★
使用 AI 進行人臉辨識應用時,可能引發的主要隱私擔憂是?
答案解析
人臉辨識 (Facial Recognition) 技術涉及收集和處理個人的生物特徵 (Biometric Data),這屬於高度敏感的個人資料。其廣泛應用引發了對大規模監控、追蹤個人行踪、資料庫安全以及潛在歧視性應用的擔憂,對個人隱私權構成重大挑戰。
#22
★★★
下列哪項措施有助於提高 AI 系統抵禦對抗性攻擊 (Adversarial Attack) 的能力?
答案解析
對抗訓練 (Adversarial Training) 是一種提高模型穩健性 (Robustness) 的方法。它透過在訓練過程中故意向模型輸入對抗樣本(經過微小擾動以欺騙模型的數據),讓模型學會識別和抵抗這些擾動,從而提高其在面對真實世界中可能的對抗性攻擊時的防禦能力。
#23
★★★★
根據台灣《個資法》(PDPA),非公務機關蒐集或處理個人資料,原則上應具備下列何者條件?
答案解析
《個資法》(PDPA) 第 19 條規定,非公務機關對個人資料之蒐集或處理,應有特定目的,並需符合下列情形之一:法律明文規定、與當事人有契約或類似契約關係且已適當告知、當事人自行公開或其他合法公開、學術研究需要(經去識別化)、經當事人同意、為增進公共利益所必要、取自一般可得來源(除非當事人表示拒絕)、對當事人權益無侵害。
#24
★★★
依據資料隱私 (Data Privacy) 的儲存限制 (Storage Limitation) 原則,個人資料應如何保存?
答案解析
儲存限制 (Storage Limitation) 原則要求,得以識別當事人之形式保存的個人資料,其保存時間不應超過達成其處理目的所必需的時間。一旦資料處理的目的達成或消失,除非有其他法律要求或基於公共利益(如存檔、科研)的理由,否則應將資料刪除或匿名化。
#25
★★★★
防止未經授權的網路流量進入內部網路的常用安全設備是?
答案解析
防火牆 (Firewall) 是一種網路安全系統,它根據預先設定的安全規則,監控並控制進出網路的流量。其主要功能是作為內部私有網路與外部公共網路(如網際網路)之間的屏障,阻止未經授權的訪問和惡意流量。防毒軟體主要偵測和清除惡意軟體,IDS 主要偵測可疑活動並發出警報。
#26
★★★★
使用 AI 進行履歷篩選時,若模型因學習到歷史數據中男性工程師比例較高的模式,而傾向於篩掉女性候選人,即使她們資格相當,這暴露了 AI 應用的哪項隱私或倫理風險 (Privacy or Ethical Risk)?
答案解析
這個例子說明了 AI 可能會學習並複製訓練數據中存在的社會偏見。如果歷史數據反映了性別不平等的狀況,AI 模型可能會無意中將這種偏見固化甚至放大,導致對特定群體(如此例中的女性)產生歧視性的結果,違反了公平性 (Fairness) 原則。
#27
★★★
確保 AI 系統在受到干擾或非預期輸入時仍能維持正常運作,不易崩潰或產生嚴重錯誤,這是指 AI 系統的哪個特性?
答案解析
穩健性 (Robustness) 指的是 AI 系統在面對各種預期或非預期情況(如數據噪音、輸入錯誤、對抗性攻擊、環境變化)時,仍能保持其功能和性能穩定,不容易失效或產生災難性錯誤的能力。這是確保 AI 系統安全可靠的關鍵特性。參考《金融業運用人工智慧(AI)指引》第四章。
#28
★★★★
《金融業運用人工智慧(AI)指引》是屬於哪種類型的規範?
答案解析
《金融業運用人工智慧(AI)指引》在其前言中明確指出,「本指引係屬行政指導性質 (Administrative Guidance),不具拘束力,旨在鼓勵金融業在風險可控之情況下,導入、使用及管理 AI」。它是由金融監督管理委員會 (FSC) 發布,提供金融業者在應用 AI 時應考量的原則和建議作法。
#29
★★★
根據台灣《資通安全管理法》,其主要目的為何?
答案解析
《資通安全管理法》的立法目的在於積極推動國家資通安全政策,加速建構國家資通安全環境,以保障國家安全,維護社會公共利益。其規範對象主要為公務機關及特定非公務機關(如關鍵基礎設施提供者),要求其建立資通安全維護計畫、通報應變機制等。在 AI 應用中,涉及到的系統、網路和數據安全,皆與此法相關。
#30
★★★
在《公部門人工智慧應用參考手冊》4.5 節討論 AI 治理時,提到的AI 應用清單 (AI Application Inventory) 應包含哪些資訊?
答案解析
建立AI 應用清單 (AI Application Inventory) 的目的是為了全面掌握組織內的 AI 應用狀況。因此,清單應包含足夠詳細的資訊,如手冊中提到的:系統用途、使用情況、相關風險、所用資料、系統所有權、開發紀錄、關鍵日期(開發、部署、更新)等,以便進行有效的治理和管理。